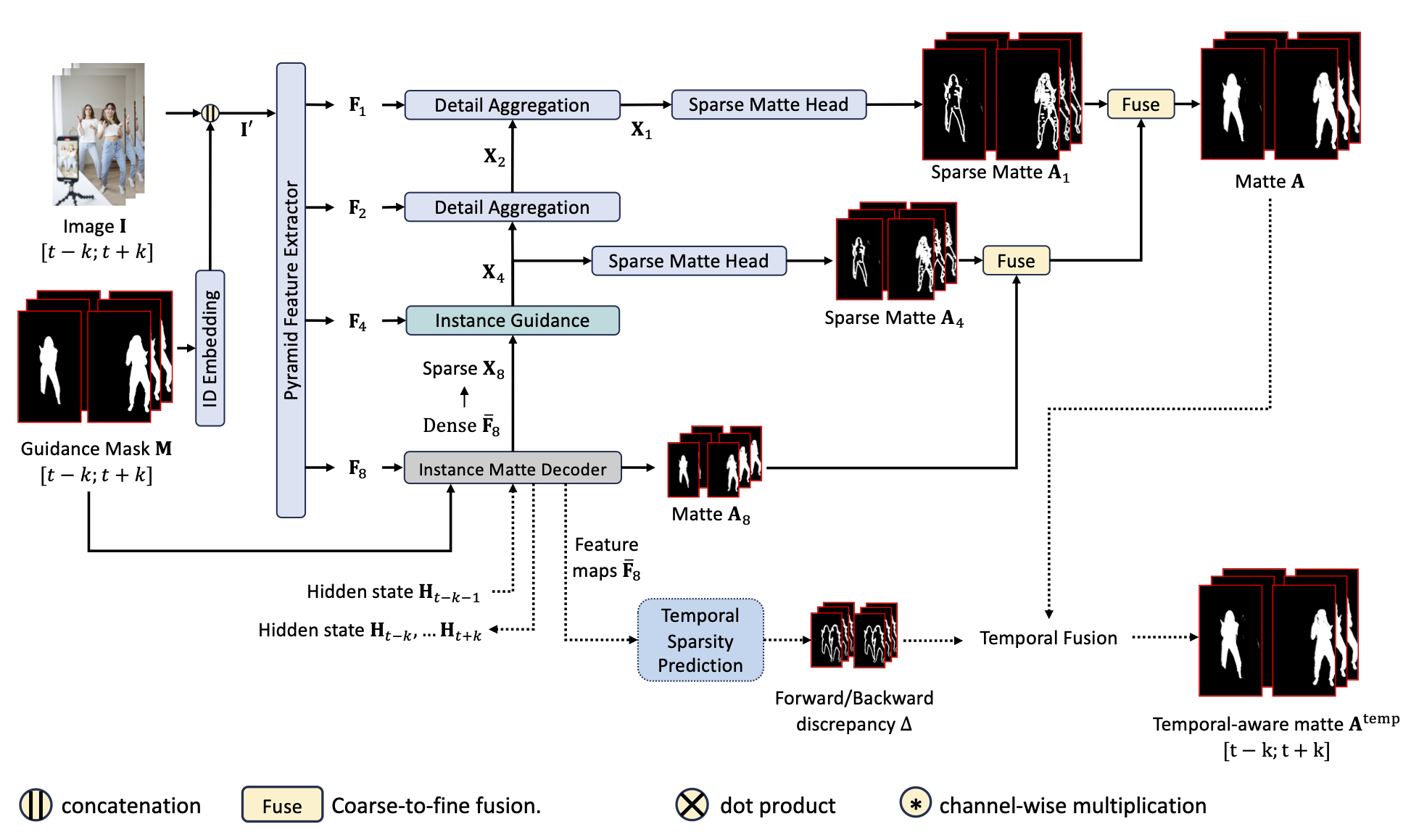
Human matting is a foundation task in image and video processing where human foreground pixels are extracted from the input. Prior works either improve the accuracy by additional guidance or improve the temporal consistency of a single instance across frames. We propose a new framework MaGGIe, Masked Guided Gradual Human Instance Matting, which predicts alpha mattes progressively for each human instances while maintaining the computational efficiency, output accuracy, and frame-by-frame consistency. Our method leverages modern architectures, including transformer attention and sparse convolution, to output all instance mattes simultaneously without exploding memory and latency. Although keeping constant inference costs in the multiple-instance scenario, our framework achieves robust and versatile performance on our proposed synthesized benchmarks. With the higher quality image and video matting benchmarks, the novel multi-instance synthesis approach from publicly available sources is introduced to increase the generalization of models in real-world scenarios.
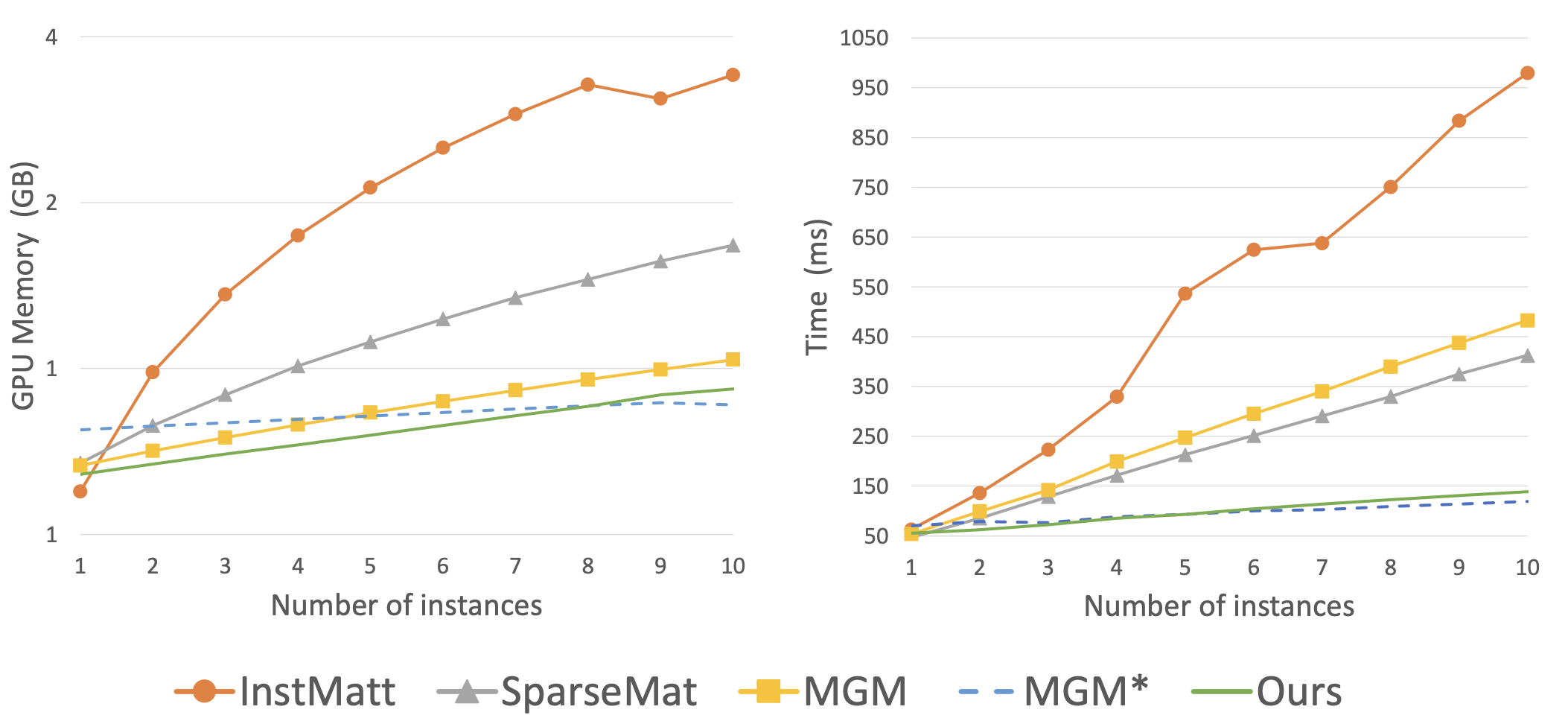
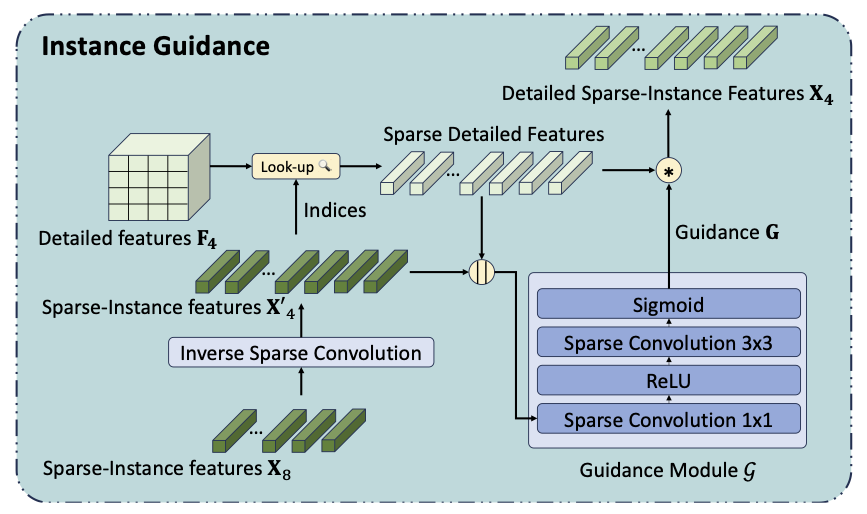
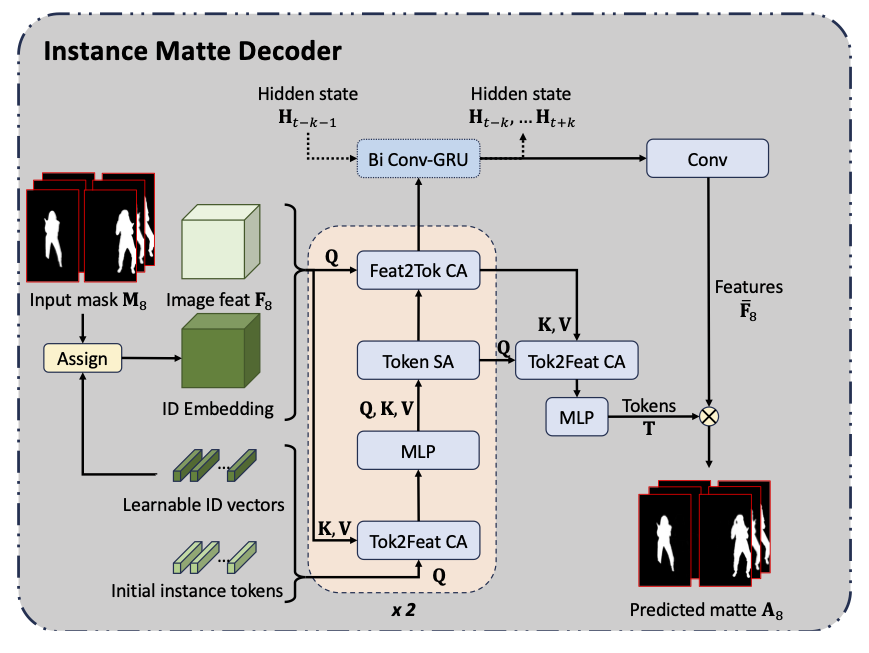
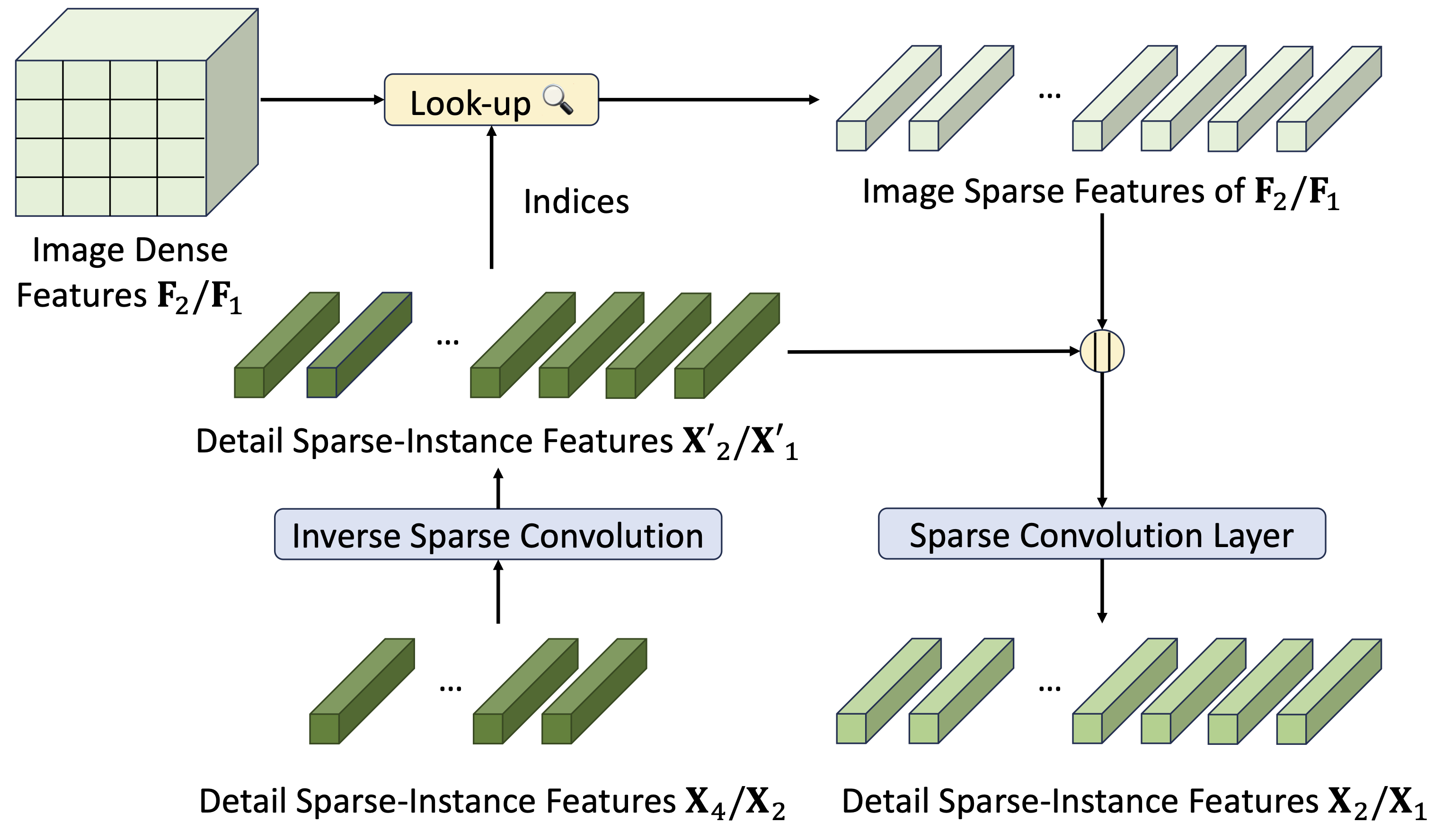
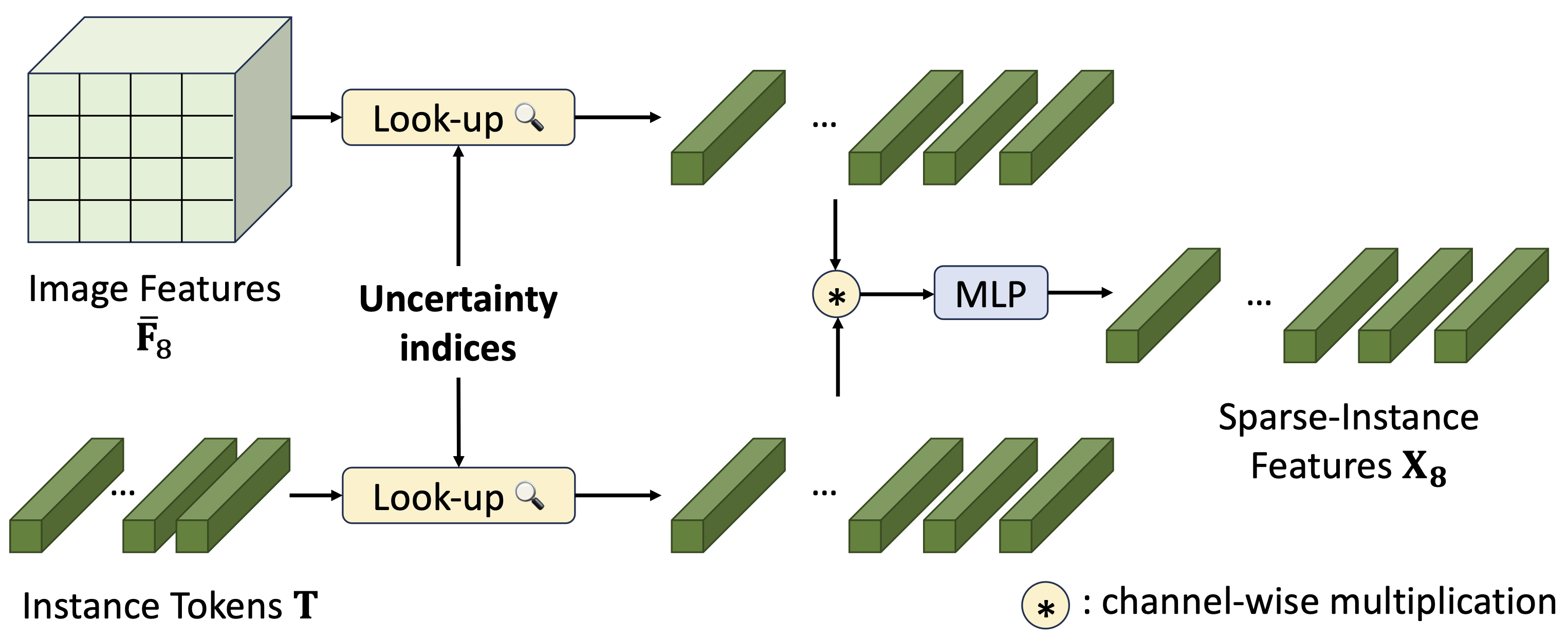
We design an efficient framework that leverages Transformer attention and Sparse convolution to progressively predict human instance mattes from binary masks:
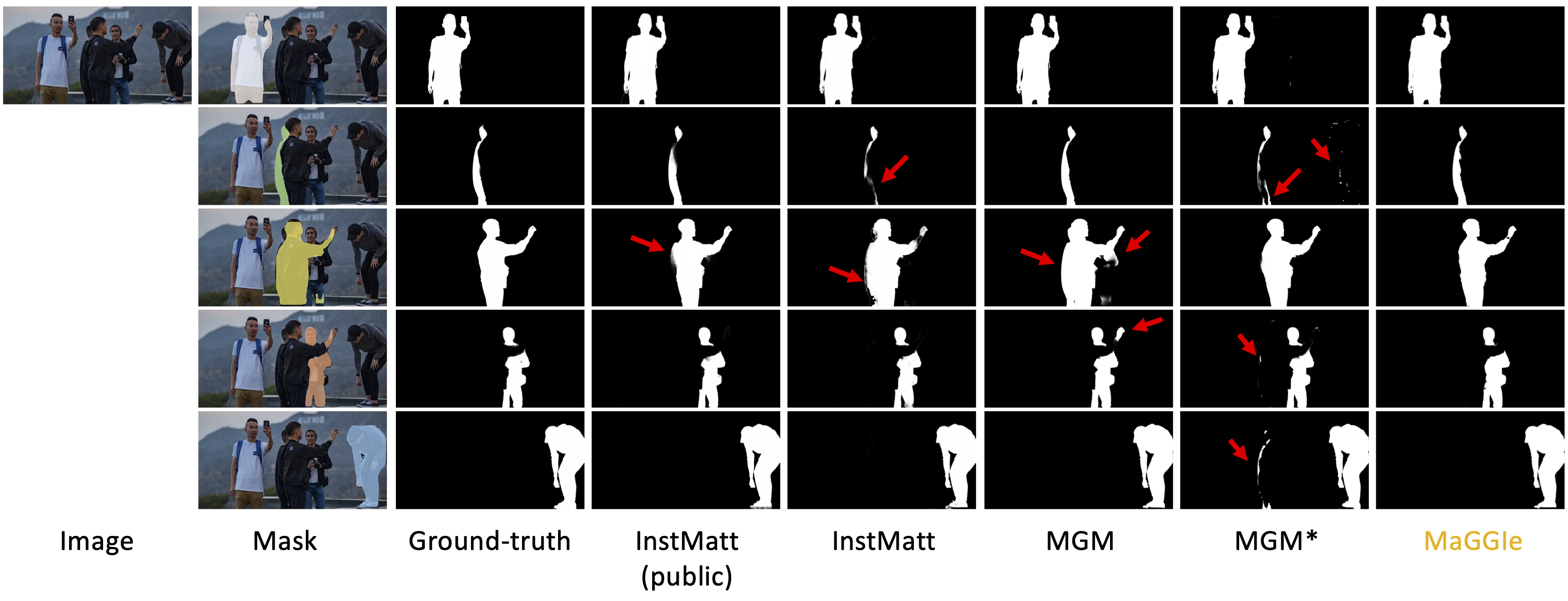
We generate different masks from COCO-pretrained Mask-RCNN to benchmark the robustness of the models.




We synthesized the human video instance matting dataset from public datasets: VideoMatte240K, VM108, and CRGNN with three difficulty levels: Easy, Medium, and Hard.
Video
Ground-truth
Without training on real image data, our method can work well on natural images. We compare our method with the state-of-the-art methods on the image human instance matting task. (Click to open image in full size)



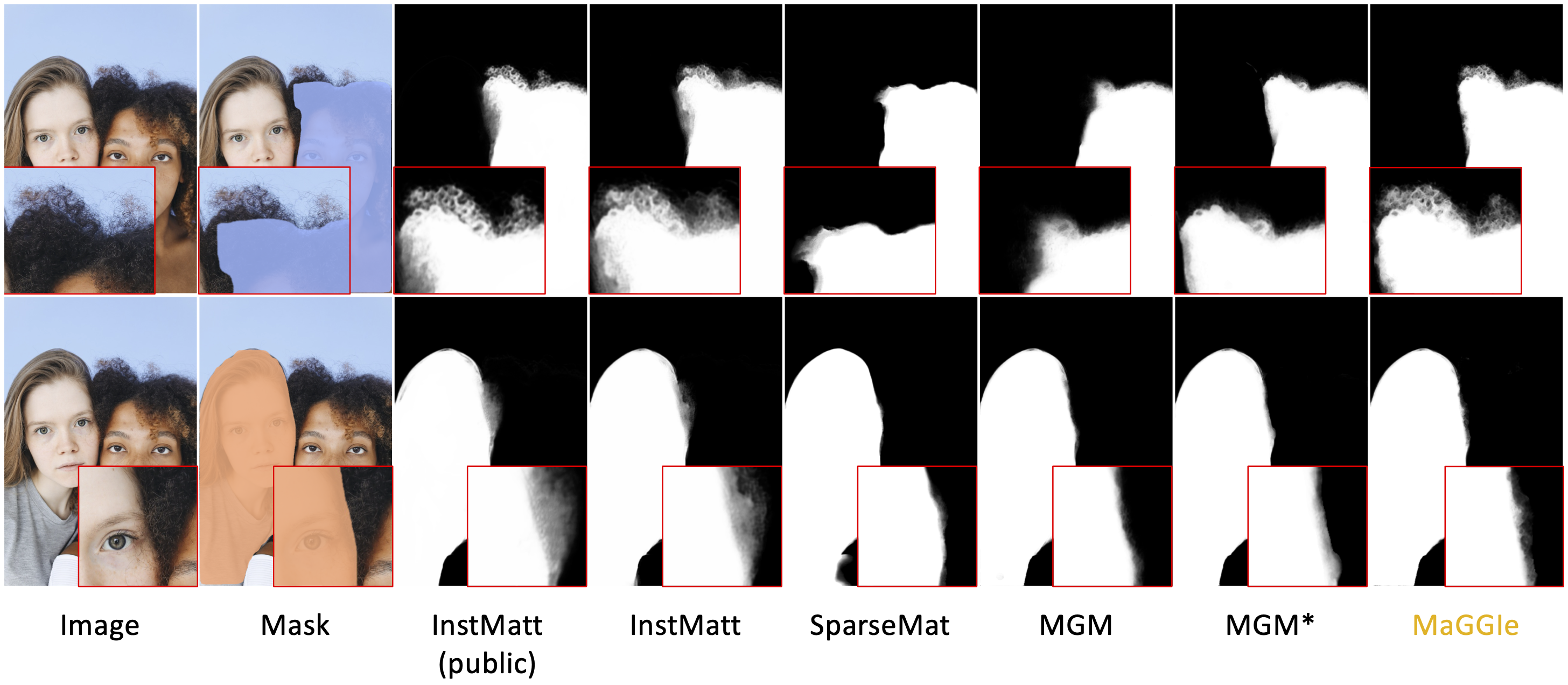

Without training on real video data, our method can generalize well to real-world scenarios. We compare our method with the state-of-the-art methods on the video human instance matting task.
Input
MaGGIe
Training only on human matting datasets, our method showcases its versatility by working well on various objects.





@InProceedings{huynh2024maggie,
author = {Huynh, Chuong and Oh, Seoung Wug and and Shrivastava, Abhinav and Lee, Joon-Young},
title = {MaGGIe: Masked Guided Gradual Human Instance Matting},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
We thank Markus Woodson for his early discussions and feedback on the project. We also thank the anonymous reviewers for their valuable comments and suggestions. I am grateful to the support of my wife Quynh in proofreading the paper.





